TESLA PCIe V100 32G + Z10PE-D16 WS Unboxing-Part 4(YOLOV5 Train Custom Dataset)
Let’s look at the predicted results:






Testing Environment:
CPU: Intel(R) Xeon(R) CPU E5–2620 v4 @ 2.10GHz
RAM: 128G
GPU: Tesla v100 32G
HD: TOSHIBA 4T(MG04ACA400E)
Motherboard: Z10PE-D16 WS
Power: Corsair HX1000
OS: Ubuntu 18.04
Before you start:
1. Clone YOLOV5 repo
cd ~/
git clone https://github.com/ultralytics/yolov5
2. Install
mv yolov5 yolov5-v3 (optional)
cd yolov5-v3
pip install -qr requirements.txt
Note: V2 and V3 release will not operate correctly with V1 pre-trained Models. If you need the last commit before v2.0 that operates correctly with all earlier pre-trained models is:
https://github.com/ultralytics/yolov5/tree/5e970d45c44fff11d1eb29bfc21bed9553abf986
Train On Custom Data
1.Prepare the labeled mask dataset as the data for this experiment.
If you want to try to get more datasets, you can download them from https://blog.roboflow.com/
Note that you must confirm that the label is in yolo format
An example of original photos:

The label content:
0 0.1285 0.048270893371757925 0.016 0.023054755043227664
0 0.088 0.19992795389048992 0.019 0.029538904899135448
2 0.1395 0.2896253602305475 0.024 0.03314121037463977
0 0.129 0.37211815561959655 0.028 0.03962536023054755
0 0.17675 0.37824207492795386 0.0165 0.037463976945244955
0 0.01675 0.4819884726224784 0.0245 0.040345821325648415
0 0.07075 0.46361671469740634 0.0255 0.030979827089337175
0 0.131 0.4755043227665706 0.028 0.037463976945244955
2 0.11275 0.5706051873198847 0.0275 0.040345821325648415
0 0.07425 0.7060518731988472 0.0265 0.03170028818443804
2 0.16 0.6329250720461095 0.023 0.03962536023054755
0 0.3615 0.01909221902017291 0.018 0.02521613832853026
0 0.35225 0.057997118155619594 0.0215 0.030979827089337175
0 0.31675 0.09329971181556196 0.0155 0.026657060518731988
0 0.3 0.12103746397694524 0.015 0.027377521613832854
0 0.265 0.14913544668587897 0.02 0.027377521613832854
0 0.244 0.23955331412103748 0.017 0.02377521613832853
2 0.21275 0.25 0.0175 0.024495677233429394
0 0.22225 0.2842219020172911 0.0195 0.028097982708933718
2 0.266 0.2910662824207493 0.021 0.02881844380403458
0 0.26375 0.4027377521613833 0.0205 0.0345821325648415
2 0.28425 0.4520893371757925 0.0175 0.029538904899135448
1 0.289 0.5630403458213257 0.028 0.04250720461095101
0 0.26125 0.6123919308357348 0.0295 0.043227665706051875
0 0.3245 0.7780979827089337 0.033 0.04899135446685879
0 0.2455 0.9495677233429395 0.038 0.056195965417867436
0 0.4535 0.018011527377521614 0.011 0.020172910662824207
0 0.4175 0.05763688760806916 0.015 0.025936599423631124
0 0.3925 0.06952449567723343 0.017 0.02377521613832853
2 0.40125 0.11779538904899135 0.0135 0.02377521613832853
0 0.43075 0.10626801152737753 0.0185 0.032420749279538905
0 0.325 0.20893371757925072 0.019 0.027377521613832854
0 0.39775 0.2053314121037464 0.0175 0.02881844380403458
2 0.3455 0.2413544668587896 0.02 0.03025936599423631
2 0.3005 0.2712536023054755 0.017 0.028097982708933718
0 0.3675 0.29430835734870314 0.022 0.032420749279538905
0 0.342 0.3706772334293948 0.023 0.028097982708933718
0 0.453 0.32780979827089335 0.022 0.0345821325648415
0 0.42025 0.37175792507204614 0.0245 0.02881844380403458
0 0.35575 0.46145533141210376 0.0195 0.03674351585014409
0 0.43125 0.43371757925072046 0.0235 0.03890489913544669
0 0.37575 0.6246397694524496 0.0255 0.04178674351585014
0 0.37975 0.7006484149855908 0.0255 0.04250720461095101
0 0.4095 0.7121757925072046 0.029 0.04394812680115274
0 0.412 0.9376801152737753 0.036 0.05403458213256484
0 0.461 0.792507204610951 0.017 0.03602305475504323
0 0.46975 0.5893371757925072 0.0265 0.040345821325648415
0 0.45425 0.5493515850144092 0.0255 0.029538904899135448
0 0.476 0.06880403458213256 0.013 0.02089337175792507
0 0.54475 0.03386167146974063 0.0125 0.021613832853025938
0 0.50875 0.07780979827089338 0.0125 0.011527377521613832
0 0.53925 0.10698847262247839 0.0165 0.02521613832853026
0 0.57325 0.06340057636887608 0.0165 0.025936599423631124
0 0.49625 0.14085014409221902 0.0165 0.028097982708933718
0 0.532 0.2010086455331412 0.01 0.018731988472622477
0 0.50675 0.24063400576368876 0.0205 0.024495677233429394
0 0.561 0.3007925072046109 0.019 0.030979827089337175
0 0.4845 0.36635446685878964 0.02 0.035302593659942365
0 0.55625 0.34942363112391933 0.0195 0.02881844380403458
0 0.53775 0.37860230547550433 0.0225 0.03962536023054755
0 0.49575 0.45713256484149856 0.0195 0.03386167146974063
0 0.629 0.010806916426512969 0.015 0.020172910662824207
0 0.64025 0.08861671469740634 0.0165 0.025936599423631124
0 0.667 0.07060518731988473 0.014 0.023054755043227664
0 0.693 0.08789625360230548 0.011 0.021613832853025938
0 0.70225 0.09402017291066282 0.0145 0.02521613832853026
2 0.6765 0.13904899135446686 0.013 0.023054755043227664
0 0.73425 0.10951008645533142 0.0155 0.025936599423631124
2 0.737 0.14301152737752162 0.015 0.02521613832853026
0 0.70975 0.2042507204610951 0.0175 0.026657060518731988
2 0.645 0.16930835734870317 0.017 0.021613832853025938
1 0.6235 0.18912103746397693 0.019 0.030979827089337175
0 0.63525 0.3000720461095101 0.0185 0.02521613832853026
0 0.60425 0.39517291066282423 0.0245 0.030979827089337175
0 0.6695 0.3872478386167147 0.02 0.028097982708933718
0 0.59625 0.5255763688760807 0.0275 0.030979827089337175
0 0.60375 0.7622478386167147 0.0325 0.0446685878962536
0 0.54775 0.8713976945244957 0.0345 0.051152737752161385
0 0.647 0.829971181556196 0.033 0.04610951008645533
0 0.766 0.0111671469740634 0.016 0.02089337175792507
0 0.82 0.07672910662824207 0.015 0.026657060518731988
2 0.8385 0.09293948126801153 0.014 0.021613832853025938
0 0.82075 0.1440922190201729 0.0125 0.023054755043227664
0 0.82675 0.17182997118155618 0.0175 0.02521613832853026
0 0.774 0.2420749279538905 0.02 0.03170028818443804
0 0.81925 0.3072766570605187 0.0185 0.030979827089337175
0 0.69625 0.4275936599423631 0.0215 0.035302593659942365
0 0.73125 0.40453890489913547 0.0215 0.032420749279538905
0 0.718 0.46397694524495675 0.025 0.0345821325648415
0 0.72675 0.5392651296829971 0.0215 0.04106628242074928
0 0.69875 0.5561959654178674 0.0275 0.043227665706051875
0 0.75675 0.9185878962536023 0.0345 0.053314121037463975
0 0.9025 0.9787463976945245 0.039 0.04250720461095101
0 0.96525 0.9845100864553314 0.0375 0.030979827089337175
0 0.90775 0.80835734870317 0.0325 0.043227665706051875
0 0.94175 0.7867435158501441 0.0285 0.05187319884726225
0 0.94375 0.6062680115273775 0.0285 0.04394812680115274
0 0.9445 0.5353025936599424 0.027 0.037463976945244955
0 0.99475 0.49063400576368876 0.0105 0.03602305475504323
0 0.8975 0.47946685878962536 0.02 0.019452449567723344
0 0.91475 0.4376801152737752 0.0225 0.03386167146974063
0 0.882 0.3760806916426513 0.022 0.0345821325648415
0 0.92475 0.32204610951008644 0.0195 0.0345821325648415
0 0.8715 0.3224063400576369 0.021 0.032420749279538905
0 0.85075 0.28278097982708933 0.0185 0.032420749279538905
0 0.90825 0.27593659942363113 0.0135 0.023054755043227664
0 0.855 0.22370317002881845 0.019 0.028097982708933718
0 0.87025 0.16822766570605188 0.0165 0.026657060518731988
0 0.961 0.18371757925072046 0.011 0.025936599423631124
0 0.982 0.10662824207492795 0.016 0.024495677233429394
0 0.8955 0.07348703170028818 0.016 0.024495677233429394
0 0.86925 0.043227665706051875 0.0135 0.024495677233429394
0 0.93 0.052953890489913544 0.015 0.019452449567723344
2 0.9575 0.030979827089337175 0.012 0.020172910662824207
2 0.99375 0.07204610951008646 0.0125 0.020172910662824207
— — — — — — — — — — — — — — — — — — — — — — — — — — -
If you want to label yourself, consider the following tools:
https://github.com/opencv/cvat
— — — — — — — — — — — — — — — — — — — — — — — — — — -
Define configuration according to our classification requirements. Put this file into the models directory:
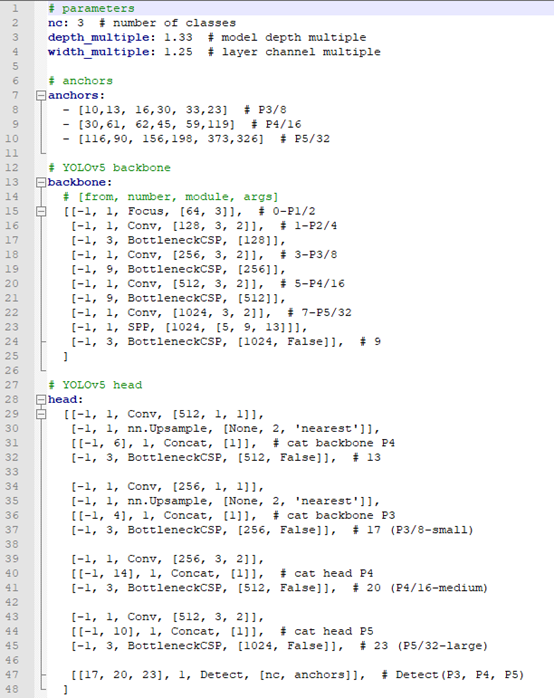
This into the data:
Training model
Distribution of labels:
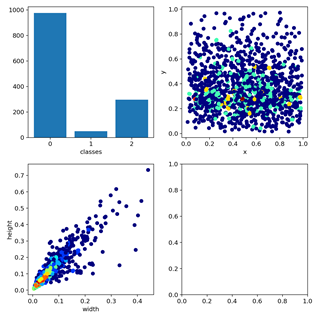
Photo overview of each batch:

Result:
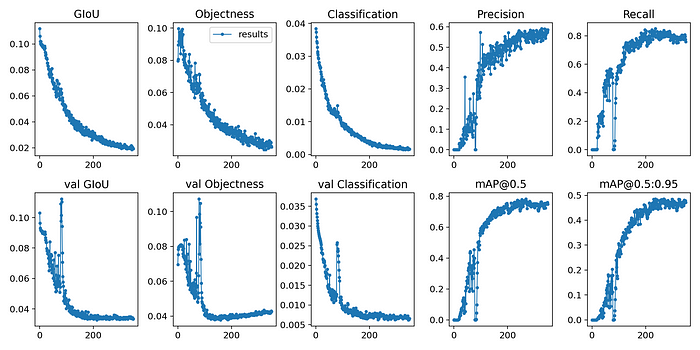
Comparison of training efficiency
350 epochs completed in 12.409 hours V.S. 350 epochs completed in 5.447 hours.
Using traditional methods:
Using CUDA device0 _CudaDeviceProperties(name=’Tesla V100-PCIE-32GB’, total_memory=32510MB)
Namespace(adam=False, batch_size=16, bucket=’’, cache_images=False, cfg=’./models/JG3.yaml’, data=’./data/JG3.yaml’, device=’0', epochs=350, evolve=False, global_rank=-1, hyp=’data/hyp.scratch.yaml’, img_size=[640, 640], local_rank=-1, logdir=’runs/’, multi_scale=False, name=’’, noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights=’’, workers=8, world_size=1)
Start Tensorboard with “tensorboard — logdir runs/”, view at http://localhost:6006/
Hyperparameters {‘lr0’: 0.01, ‘momentum’: 0.937, ‘weight_decay’: 0.0005, ‘giou’: 0.05, ‘cls’: 0.5, ‘cls_pw’: 1.0, ‘obj’: 1.0, ‘obj_pw’: 1.0, ‘iou_t’: 0.2, ‘anchor_t’: 4.0, ‘fl_gamma’: 0.0, ‘hsv_h’: 0.015, ‘hsv_s’: 0.7, ‘hsv_v’: 0.4, ‘degrees’: 0.0, ‘translate’: 0.1, ‘scale’: 0.5, ‘shear’: 0.0, ‘perspective’: 0.0, ‘flipud’: 0.0, ‘fliplr’: 0.5, ‘mixup’: 0.0}from n params module arguments
0 -1 1 8800 models.common.Focus [3, 80, 3]
1 -1 1 115520 models.common.Conv [80, 160, 3, 2]
2 -1 1 315680 models.common.BottleneckCSP [160, 160, 4]
3 -1 1 461440 models.common.Conv [160, 320, 3, 2]
4 -1 1 3311680 models.common.BottleneckCSP [320, 320, 12]
5 -1 1 1844480 models.common.Conv [320, 640, 3, 2]
6 -1 1 13228160 models.common.BottleneckCSP [640, 640, 12]
7 -1 1 7375360 models.common.Conv [640, 1280, 3, 2]
8 -1 1 4099840 models.common.SPP [1280, 1280, [5, 9, 13]]
9 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
10 -1 1 820480 models.common.Conv [1280, 640, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, ‘nearest’]
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 5435520 models.common.BottleneckCSP [1280, 640, 4, False]
14 -1 1 205440 models.common.Conv [640, 320, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, ‘nearest’]
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 1360960 models.common.BottleneckCSP [640, 320, 4, False]
18 -1 1 922240 models.common.Conv [320, 320, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 5025920 models.common.BottleneckCSP [640, 640, 4, False]
21 -1 1 3687680 models.common.Conv [640, 640, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
24 [17, 20, 23] 1 53832 models.yolo.Detect [3, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [320, 640, 1280]]
Model Summary: 407 layers, 8.84471e+07 parameters, 8.84471e+07 gradientsOptimizer groups: 134 .bias, 142 conv.weight, 131 other
Scanning images: 100%|██████████████████████| 208/208 [00:00<00:00, 3860.96it/s]
Scanning labels ../mouth_mask_yolo_GPU/train.cache (199 found, 0 missing, 9 empty, 0 duplicate, for 208 images): 208it [00:00, 10349.92it/s]
Scanning images: 100%|████████████████████████| 83/83 [00:00<00:00, 3922.69it/s]
Scanning labels ../mouth_mask_yolo_GPU/val.cache (83 found, 0 missing, 0 empty, 0 duplicate, for 83 images): 83it [00:00, 8512.29it/s]Analyzing anchors… anchors/target = 5.46, Best Possible Recall (BPR) = 0.9977
Image sizes 640 train, 640 test
Using 8 dataloader workers
Starting training for 350 epochs…Epoch gpu_mem GIoU obj cls total targets img_size
0/349 25.4G 0.112 0.07871 0.03836 0.2291 230 640
Class Images Targets P R mAP@.5
all 83 496 0 0 8.25e-05 1.21e-05Epoch gpu_mem GIoU obj cls total targets img_size
1/349 25.3G 0.106 0.08621 0.03719 0.2294 251 640
Class Images Targets P R mAP@.5
all 83 496 0.00071 0.0537 0.000265 4.02e-05……
Epoch gpu_mem GIoU obj cls total targets img_size
349/349 25.3G 0.02255 0.03052 0.001988 0.05506 150 640
Class Images Targets P R mAP@.5
all 83 496 0.542 0.794 0.737 0.457
Optimizer stripped from runs/exp0/weights/last.pt, 177.5MB
Optimizer stripped from runs/exp0/weights/best.pt, 177.5MB
350 epochs completed in 12.409 hours.
Use memory as a carrier:
Using CUDA device0 _CudaDeviceProperties(name=’Tesla V100-PCIE-32GB’, total_memory=32510MB)
Namespace(adam=False, batch_size=16, bucket=’’, cache_images=False, cfg=’./models/JG3.yaml’, data=’./data/JG3.yaml’, device=’0', epochs=350, evolve=False, global_rank=-1, hyp=’data/hyp.scratch.yaml’, image_weights=False, img_size=[640, 640], local_rank=-1, logdir=’runs/’, multi_scale=False, name=’’, noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights=’’, workers=8, world_size=1)
Start Tensorboard with “tensorboard — logdir runs/”, view at http://localhost:6006/
Hyperparameters {‘lr0’: 0.01, ‘lrf’: 0.2, ‘momentum’: 0.937, ‘weight_decay’: 0.0005, ‘giou’: 0.05, ‘cls’: 0.5, ‘cls_pw’: 1.0, ‘obj’: 1.0, ‘obj_pw’: 1.0, ‘iou_t’: 0.2, ‘anchor_t’: 4.0, ‘fl_gamma’: 0.0, ‘hsv_h’: 0.015, ‘hsv_s’: 0.7, ‘hsv_v’: 0.4, ‘degrees’: 0.0, ‘translate’: 0.1, ‘scale’: 0.5, ‘shear’: 0.0, ‘perspective’: 0.0, ‘flipud’: 0.0, ‘fliplr’: 0.5, ‘mixup’: 0.0}from n params module arguments
0 -1 1 8800 models.common.Focus [3, 80, 3]
1 -1 1 115520 models.common.Conv [80, 160, 3, 2]
2 -1 1 315680 models.common.BottleneckCSP [160, 160, 4]
3 -1 1 461440 models.common.Conv [160, 320, 3, 2]
4 -1 1 3311680 models.common.BottleneckCSP [320, 320, 12]
5 -1 1 1844480 models.common.Conv [320, 640, 3, 2]
6 -1 1 13228160 models.common.BottleneckCSP [640, 640, 12]
7 -1 1 7375360 models.common.Conv [640, 1280, 3, 2]
8 -1 1 4099840 models.common.SPP [1280, 1280, [5, 9, 13]]
9 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
10 -1 1 820480 models.common.Conv [1280, 640, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, ‘nearest’]
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 5435520 models.common.BottleneckCSP [1280, 640, 4, False]
14 -1 1 205440 models.common.Conv [640, 320, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, ‘nearest’]
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 1360960 models.common.BottleneckCSP [640, 320, 4, False]
18 -1 1 922240 models.common.Conv [320, 320, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 5025920 models.common.BottleneckCSP [640, 640, 4, False]
21 -1 1 3687680 models.common.Conv [640, 640, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
24 [17, 20, 23] 1 53832 models.yolo.Detect [3, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [320, 640, 1280]]
Model Summary: 407 layers, 8.84471e+07 parameters, 8.84471e+07 gradientsOptimizer groups: 134 .bias, 142 conv.weight, 131 other
Scanning images: 100%|██████████████████████| 208/208 [00:00<00:00, 3476.27it/s]
Scanning labels ../mouth_mask_yolo_GPU/train.cache (199 found, 0 missing, 9 empty, 0 duplicate, for 208 images): 208it [00:00, 10407.58it/s]
Scanning images: 100%|████████████████████████| 83/83 [00:00<00:00, 1846.52it/s]
Scanning labels ../mouth_mask_yolo_GPU/val.cache (83 found, 0 missing, 0 empty, 0 duplicate, for 83 images): 83it [00:00, 4136.30it/s]Analyzing anchors… anchors/target = 5.46, Best Possible Recall (BPR) = 0.9977
Image sizes 640 train, 640 test
Using 8 dataloader workers
Logging results to runs/exp0
Starting training for 350 epochs…Epoch gpu_mem GIoU obj cls total targets img_size
0/349 25.4G 0.1115 0.07953 0.03828 0.2293 230 640
Class Images Targets P R mAP@.5
all 83 496 0 0 0.000155 2.62e-05……
Epoch gpu_mem GIoU obj cls total targets img_size
349/349 25.3G 0.02087 0.02704 0.001943 0.04986 177 640
Class Images Targets P R mAP@.5
all 83 496 0.602 0.803 0.758 0.456
Optimizer stripped from runs/exp0/weights/last.pt, 177.5MB
Optimizer stripped from runs/exp0/weights/best.pt, 177.5MB
350 epochs completed in 5.447 hours.
